- Published on
MLOps Basics [Week 4]: Model Packaging - ONNX
- Authors

- Name
- Raviraja Ganta
- @raviraja_ganta
📦 Model Packaging
Why do we need model packaging? Models can be built using any machine learning framework available out there (sklearn, tensorflow, pytorch, etc.). We might want to deploy models in different environments like (mobile, web, raspberry pi) or want to run in a different framework (trained in pytorch, inference in tensorflow). A common file format to enable AI developers to use models with a variety of frameworks, tools, runtimes, and compilers will help a lot.
This is achieved by a community project ONNX.
In this post, I will be going through:
What is ONNX?How to convert a trained model to ONNX format?What is ONNX Runtime?How to run ONNX converted model in ONNX Runtime?Comparisons
What is ONNX?
ONNX is an open format built to represent machine learning models.
ONNX defines a common set of operators - the building blocks of machine learning and deep learning models - and a common file format to enable AI developers to use models with a variety of frameworks, tools, runtimes, and compilers.


The ONNX format is the basis of an open ecosystem that makes AI more accessible and valuable to all:
- developers can choose the right framework for their task
- framework authors can focus on innovative enhancements
- hardware vendors can streamline optimizations for neural network computations.

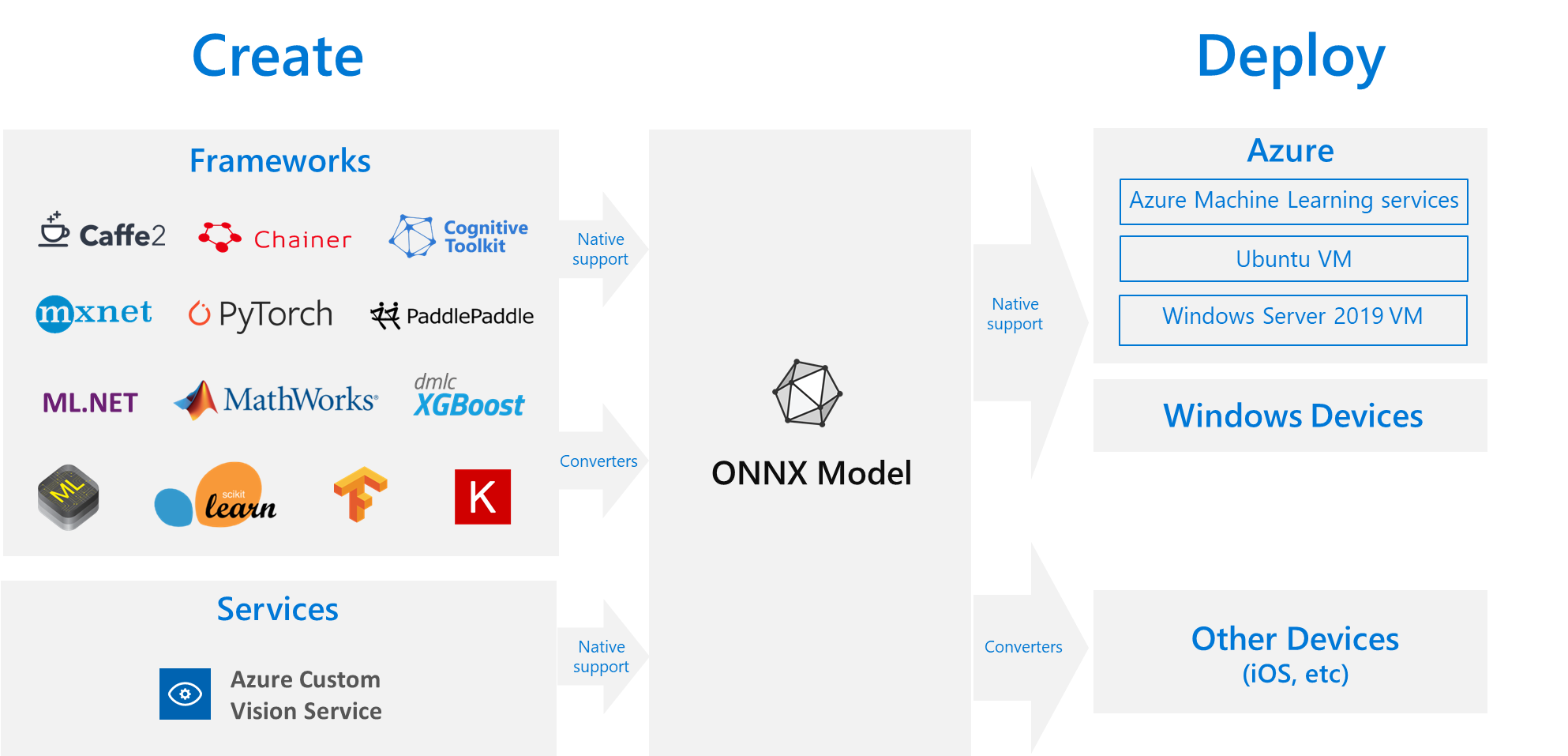
Thus, ONNX is an open file format to store (trained) machine learning models/pipelines containing sufficient detail (regarding data types etc.) to move from one platform to another.
Models in ONNX format can be easily deployed to various cloud platforms as well as to IoT devices.
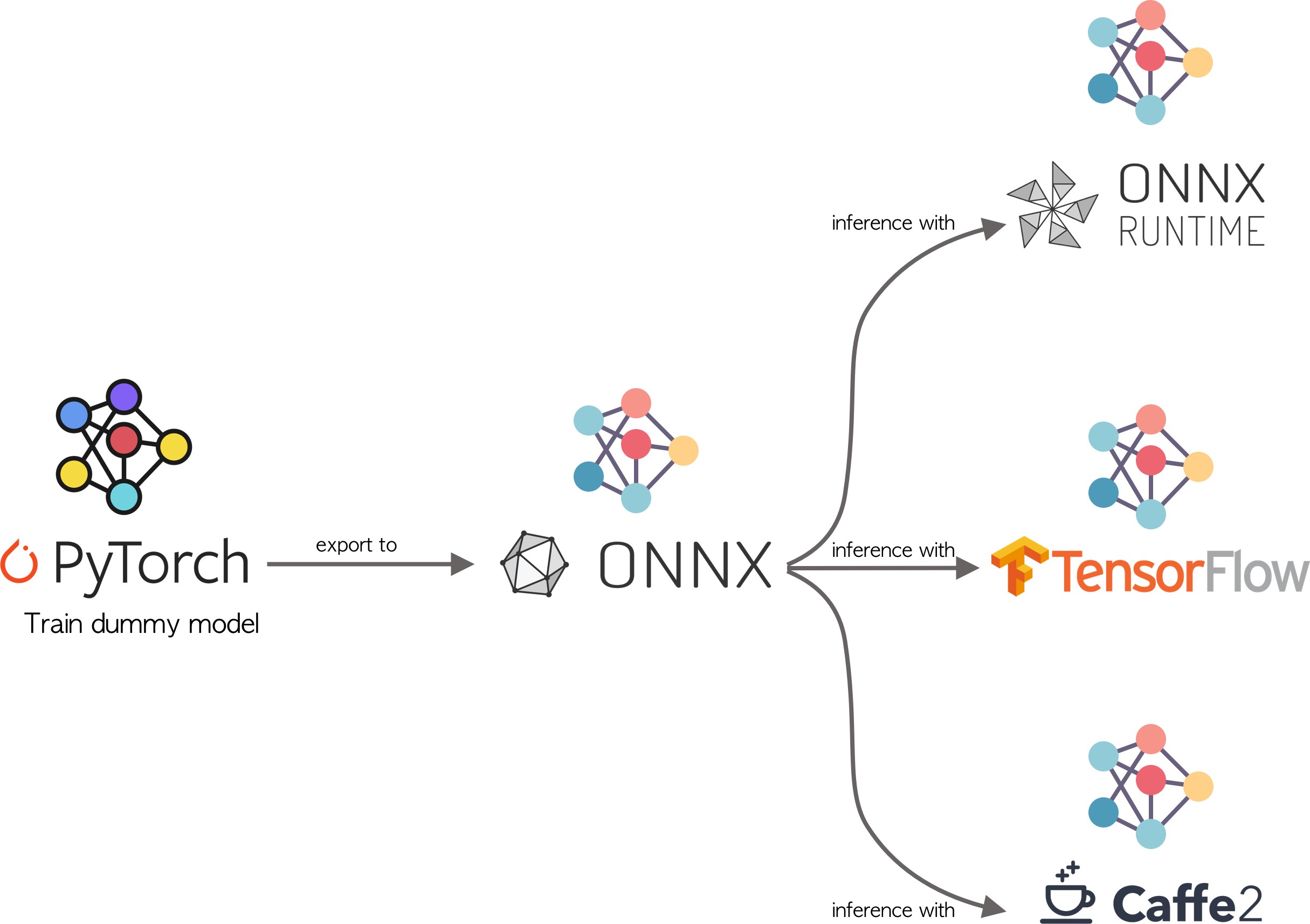
⏳ How to convert a trained model to ONNX format?
Pytorch Lightning ⚡️ which is a wrapper around Vanilla Pytorch 🍦, there are two ways to convert the model intoUsing
onnx.exportmethod in 🍦Using
to_onnxmethod in ⚡️
Exporting using model using 🍦 Pytorch
In order to convert the model into ONNX format, we need to specify some things:
Trained model which needs to be converted
model_path = f"{root_dir}/models/best-checkpoint.ckpt"
cola_model = ColaModel.load_from_checkpoint(model_path)
Sample input format (which the forward method takes with batch_size as 1)
input_batch = next(iter(data_model.train_dataloader()))
input_sample = {
"input_ids": input_batch["input_ids"][0].unsqueeze(0),
"attention_mask": input_batch["attention_mask"][0].unsqueeze(0),
}
- Input names, Output names
- Dynamic axes (batch size dimension)
Complete code looks like:
torch.onnx.export(
cola_model, # model being run
(
input_sample["input_ids"],
input_sample["attention_mask"],
), # model input (or a tuple for multiple inputs)
f"{root_dir}/models/model.onnx", # where to save the model
export_params=True,
opset_version=10,
input_names=["input_ids", "attention_mask"], # the model's input names
output_names=["output"], # the model's output names
dynamic_axes={ # variable length axes
"input_ids": {0: "batch_size"},
"attention_mask": {0: "batch_size"},
"output": {0: "batch_size"},
},
)
Exporting using model using ⚡️ Pytorch Lightning
Converting model to onnx with multi-input is not added yet. See the issue here
Let's see when the input is a single tensor.
⚡️ Module class comes with an in-built method to_onnx. Call that method with the necessary parameters:
- Name of the onnx model
- Input sample
- Input names
- Output names
- Dynamic axes
The code looks like:
model.to_onnx(
"model.onnx", # where to save the model
input_sample, # input samples with atleast batch size as 1
export_params=True,
opset_version=10,
input_names = ['input'], # Input names
output_names = ['output'], # Output names
dynamic_axes={ # variable length axes
'input' : {0 : 'batch_size'},
'output' : {0 : 'batch_size'},
},
)
👟 What is ONNX Runtime?
ONNX Runtime is a performance-focused inference engine for ONNX models.
ONNX Runtime was designed with a focus on performance and scalability in order to support heavy workloads in high-scale production scenarios. It also has extensibility options for compatibility with emerging hardware developments.

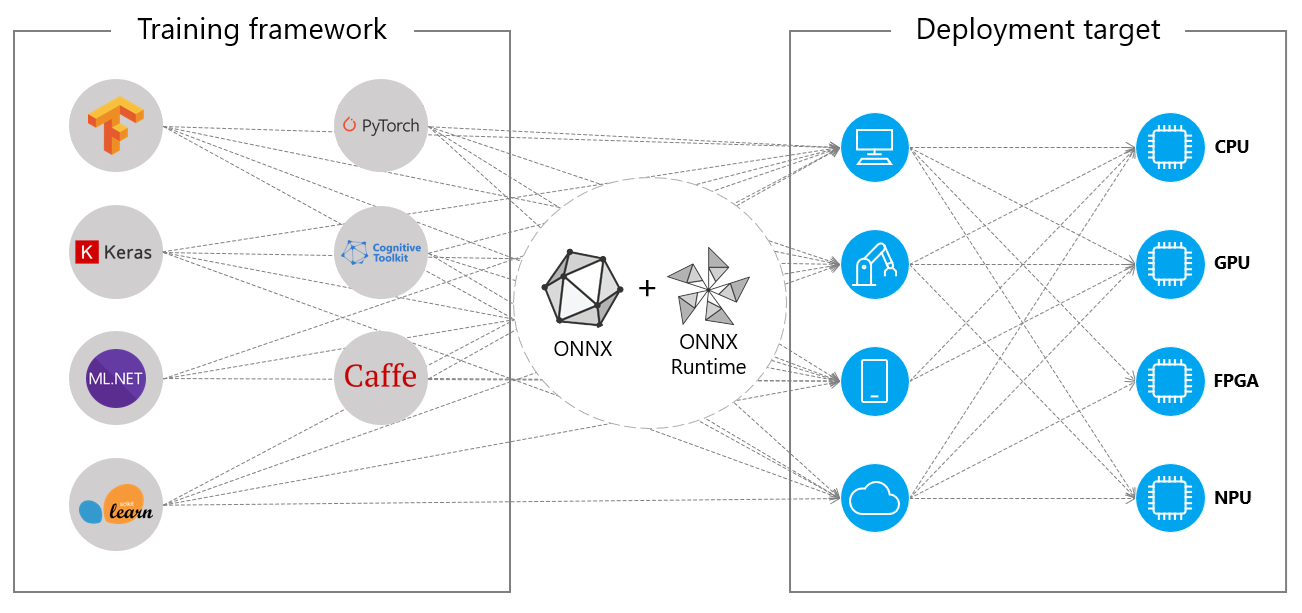
⚙️ Installation
Install onnxruntime using the following command:
pip install onnxruntime
ONNX Runtime is supported on different Operating System (OS) and hardware (HW) platforms. The Execution Provider (EP) interface in ONNX Runtime enables easy integration with different HW accelerators.
Check all the providers of ONNXRuntime using the command
from onnxruntime import get_all_providers
print(get_all_providers())
Sample output looks like:
[
'TensorrtExecutionProvider',
'CUDAExecutionProvider',
'MIGraphXExecutionProvider',
'ROCMExecutionProvider',
'OpenVINOExecutionProvider',
'DnnlExecutionProvider',
'NupharExecutionProvider',
'VitisAIExecutionProvider',
'NnapiExecutionProvider',
'ArmNNExecutionProvider',
'ACLExecutionProvider',
'DmlExecutionProvider',
'RknpuExecutionProvider',
'CPUExecutionProvider'
]
🏃♂️ How to run ONNX converted model in ONNX Runtime?
Create Inference Session which will load the onnx model
import onnxruntime as ort
ort_session = ort.InferenceSession(onnx_model_path)
Prepare the inputs for the session
The input names should match the names used while creating the onnx model.
ort_inputs = {
"input_ids": np.expand_dims(processed["input_ids"], axis=0),
"attention_mask": np.expand_dims(processed["attention_mask"], axis=0),
}
Run the session
Run the inference session with the inputs
ort_output = ort_session.run(None, ort_inputs)
None will return all the outputs. If the model return multiple outputs, specifying the output name here will return only that output
Complete code looks like:
class ColaPredictor:
def __init__(self, model_path):
# creating the onnxruntime session
self.ort_session = ort.InferenceSession(model_path)
self.processor = DataModule()
self.lables = ["unacceptable", "acceptable"]
def predict(self, text):
inference_sample = {"sentence": text}
processed = self.processor.tokenize_data(inference_sample)
# Preparing inputs
ort_inputs = {
"input_ids": np.expand_dims(processed["input_ids"], axis=0),
"attention_mask": np.expand_dims(processed["attention_mask"], axis=0),
}
# Run the model (None = get all the outputs)
ort_outs = self.ort_session.run(None, ort_inputs)
# Normalising the outputs
scores = softmax(ort_outs[0])[0]
predictions = []
for score, label in zip(scores, self.lables):
predictions.append({"label": label, "score": score})
return predictions
This is the python api example for onnxruntime. For other language support refer to the documentation here
⏲ Comparisons
Let's compare the response time for both methods (standard pytorch inference, onnxruntime inference)
Experiment: Running a sample of 10 sentences after a initial warmp-up(loading the model and running inference on 1 sentence)
Inference times of Pytorch Model
function:'predict' took: 0.00427 sec
function:'predict' took: 0.00420 sec
function:'predict' took: 0.00437 sec
function:'predict' took: 0.00587 sec
function:'predict' took: 0.00531 sec
function:'predict' took: 0.00504 sec
function:'predict' took: 0.00658 sec
function:'predict' took: 0.00491 sec
function:'predict' took: 0.00520 sec
function:'predict' took: 0.00476 sec
Inference times of ONNX format model
function:'predict' took: 0.00144 sec
function:'predict' took: 0.00128 sec
function:'predict' took: 0.00132 sec
function:'predict' took: 0.00136 sec
function:'predict' took: 0.00134 sec
function:'predict' took: 0.00132 sec
function:'predict' took: 0.00144 sec
function:'predict' took: 0.00132 sec
function:'predict' took: 0.00172 sec
function:'predict' took: 0.00187 sec
As it is visible from the logs there is an improvment of 2-3x using ONNX + ONNXRuntime formant for inference compared to standard pytorch inference.
🔚
I have used pytorch only. ONNX supports various frameworks. Look into the documentation here for more information
Complete code for this post can also be found here: Github